Extremum estimator
In statistics and econometrics, extremum estimators is a wide class of estimators for parametric models that are calculated through maximization (or minimization) of a certain objective function, which depends on the data. The general theory of extremum estimators was developed by Amemiya (1985).
Contents |
Definition
An estimator 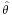 is called an extremum estimator, if there is an objective function
is called an extremum estimator, if there is an objective function 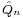 such that
such that
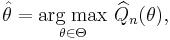
where Θ is the possible range of parameter values. Sometimes a slightly weaker definition is given:
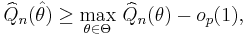
where op(1) is the variable converging in probability to zero. With this modification doesn’t have to be the exact maximizer of the objective function, just be sufficiently close to it.
The theory of extremum estimators does not specify what the objective function should be. There are various types of objective functions suitable for different models, and this framework allows us to analyse the theoretical properties of such estimators from a unified perspective. The theory only specifies the properties that the objective function has to possess, and when one selects a particular objective function, he or she only has to verify that those properties are satisfied.
Consistency
If the set Θ is compact and there is a limiting function Q0(θ) such that: 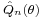 converges to Q0(θ) in probability uniformly over Θ, and the function Q0(θ) is continuous and has a unique maximum at θ = θ0. If these conditions are satisfied then is consistent for θ0.[1]
converges to Q0(θ) in probability uniformly over Θ, and the function Q0(θ) is continuous and has a unique maximum at θ = θ0. If these conditions are satisfied then is consistent for θ0.[1]
The uniform convergence in probability of means that
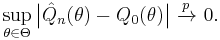
The requirement for Θ to be compact can be replaced with a weaker assumption that the maximum of Q0 was well-separated, that is there should not exist any points θ that are distant from θ0 but such that Q0(θ) were close to Q0(θ0). Formally, it means that for any sequence {θi} such that Q0(θi) → Q0(θ0), it should be true that θi → θ0.
Asymptotic normality
Examples
- Maximum likelihood estimator uses the objective function
- Generalized method of moments estimator is defined through the objective function
- Minimum distance estimator
- m-estimators
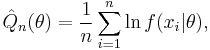
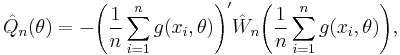
See also
Notes
- ^ Newey & McFadden (1994), Theorem 2.1
References
- Amemiya, Takeshi (1985). Advanced econometrics. Harvard University Press. ISBN 0-674-00560-0.
- Newey, Whitney K.; McFadden, Daniel (1994). Large sample estimation and hypothesis testing. Handbook of econometrics, vol.IV, Ch.36. Elsevier Science. pp. 2111–2245. ISBN 0444887660.